Глобальная лексикостатистическая база данных: материалы
Экспериментальные «древостроительные» процедуры ГЛБД:
предварительные результаты
Эту страницу на
данный момент следует воспринимать как предварительные зарисовки к более
детальной и точной картине, построение которой является основной целью ГЛБД.
Здесь выложен ряд классификационных схем (деревьев), созданных в рамках
проекта на основании (1) применения к относительно небольшим («1-го уровня»)
базам данных стандартного сравнительно-исторического
анализа; (2) попыток заменить потенциально субъективный исторический анализ
«объективной» компьютеризированной процедурой; (3) замены тщательного,
детального анализа индивидуальных списков на общий, достаточно грубый
набросок того, как в будущем мог бы выглядеть один из самых высоких уровней
ГЛБД.
1. «Стандартные» деревья
В ГЛБД на
сегодняшний день предусмотрена возможность построения генеалогического древа в
он-лайн режиме с выбором различных параметров (подробности см. в Кратком руководстве). По умолчанию «правильным» деревом
при этом считается то, которое построено в соответствии с параметром
«Фиксированная скорость» (по формуле С. А. Старостина, модифицированной по
сравнению с формулой Сводеша; скорость «распада» 100-словного списка при этом
равна 0.05% за тысячу лет) или в соответствии с параметром «Переменная
скорость» (по той же формуле, но с переменной скоростью «распада», зависящей от
индивидуальных индексов стабильности разных элементов списка Сводеша); как
правило, деревья, построенные по этим двум способам, почти не отличаются друг
от друга. В нижеследующей таблице приводятся такого рода «официальные» деревья
(включая примерные глоттохронологические датировки) по всем языковым группам,
представленным на сайте ГЛБД.
|
Языковая группа |
Фиксированная скорость |
Переменная скорость |
Языковая группа |
Фиксированная скорость |
Переменная скорость |
|
Нахская |
|
|
Сев.-койсанская |
|
|
|
Обско-угорская |
|
|
Экоидная |
|
|
2. «Объективно построенное» дерево
фонетического сходства
Это дерево
генерируется на основании примерно тех же принципов, которые задействованы для
создания гораздо более репрезентативного графа «ASJP World Language Tree of Lexical Similarity» (в последнем использован несколько более
сложный алгоритм и, самое главное, задействованы данные по общему числу языков,
более чем в 100 раз превышающему текущий инвентарь ГЛБД – с другой стороны,
алгоритм ASJP пока работает только на 40-, не на
100-словных списках, к тому же далеко не всегда составленных с надлежащим
качеством контроля за исполнением). В него включены данные по всем языкам, задействованным в ГЛБД (за
исключением новейших добавлений; само дерево обновляется раз в несколько
месяцев), обработанные следующим образом:
а. Алгоритм снимает индексы когнации,
проставленные составителями списков на основании соображений этимологического
характера;
б. Вместо старых индексов автоматически проставляются новые,
определяющие «родство» слов на основании обнаружения между ними достаточного фонетического сходства. Основное условие
сходства определяется при этом так: «первый и второй согласные в корнях сравниваемых слов относятся к
одному и тому же консонантному классу» (т. е. в словах совпадают друг с другом
основные фонетические признаки как их первых, так и их вторых согласных).
Информация о том, какие звуки/знаки представляют какие консонантные классы,
содержится в базе данных sound.dbf; с ее текущей
структурой можно ознакомиться здесь.
в. После этого алгоритм, по формуле
«переменной скорости», составляет новую лексикостатистическую матрицу и новое
генеалогическое дерево, опираясь на полученные «псевдо-индексы когнации».
Щелкните
здесь, чтобы ознакомиться с последней версией (01.14.2013) «Объективно построенного» дерева фонетического сходства.
{kind=link}
Более ранние версии: 10.19.2011, 07.31.2011.
{kind=link}
{kind=link}
Цветовая раскраска
пространства между узлами дерева расшифровывается следующим образом:
синий =
компьютеру удалось правильно распознать языковую семью или хотя бы часть
языковой семьи (правда, внутренняя структура этой семьи все равно может
содержать ошибки) = позитивный
результат;
желтый =
компьютер опознал всю или часть «сомнительной» семьи, гипотеза о существовании
которой поддерживается хотя бы некоторыми лингвистами на основании серьезной
аргументации, но пока что не нашла массовой поддержки = релевантный, но неокончательный
результат;
красный = связь
установлена на минимальном числе «псевдо-когнатов», скорее всего, неотличимом от
случайности; отражает недоказуемую (по крайней мере, в рамках данного
алгоритма) или заведомо ошибочную связь = нерелевантный
результат.
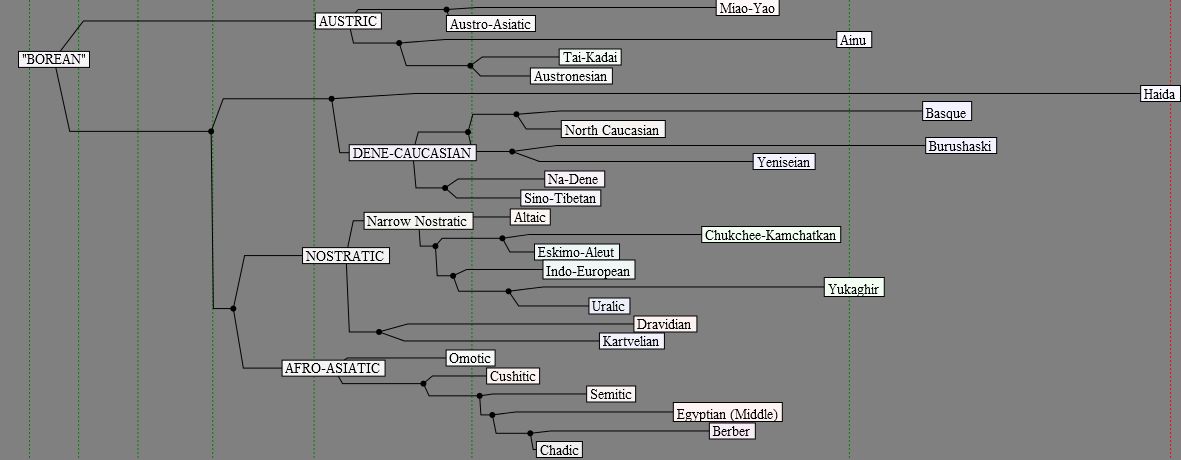
3. Предварительное генеалогическое
дерево языков Евразии (по 50-словным спискам)
Дерево является
очень грубой, в полном смысле слова предварительной «прикидкой» того, как в
дальнейшем может быть устроена типичная база «высокого уровня» в составе
ГЛБД. Оно построено по результатам ручной
индексации как надежных, так и сугубо гипотетических когнатов в пределах
50-словных списков, составленных для более чем 150 праязыков «низких уровней»
(таких, как прагерманский, пратюркский, праэфиосемитский, пранахский и т. п.)
и языков-изолятов Евразии. Основной массив базы скомпилирован Г. Старостиным
при активной поддержке А. Дыбо, А. Касьяна, М. Живлова и других коллег по
Ностратическому семинару в рамках Центра компаративистики ИВКА РГГУ.
Индексация когнатов
там, где это возможно, проводилась на основе регулярных фонетических
соответствий. Там, где языковые группы плохо изучены (в историческом плане),
а также на «макросемейных» уровнях вместо фонетических соответствий
использовалось элементарное фонетическое
сходство праформ (определяемое примерно по тем же параметрам, что и в
случае с «объективным» деревом, описанным выше). Все сопоставления проводились
с использованием «промежуточных» уровней реконструкции — в соответствии с
принципами, подробно изложенными в статье «Preliminary lexicostatistics».
Щелкните
здесь, чтобы ознакомиться с последней версией
(07.31.2011)
Предварительного
генеалогического дерева языков Евразии (длинный
вариант).
{kind=link}
Щелкните
здесь, чтобы ознакомиться с последней версией
(07.31.2011)
Предварительного
генеалогического дерева языков Евразии (короткий
вариант).
{kind=link}
Щелкните здесь, чтобы
ознакомиться с данными списков (без индексов когнации) в виде таблицы Excel (ВНИМАНИЕ: Многие из форм под
звездочкой даны в «сыром» виде и нуждаются в дополнительной тщательной проверке.
Убедительная просьба не ссылаться ни на какие
данные из этого файла без предварительной консультации с авторами по
адресу gstarst@rinet.ru).
НА ГЛАВНУЮ СТРАНИЦУ К БАЗАМ ДАННЫХ АНГЛИЙСКАЯ ВЕРСИЯ
© 2011 George Starostin (site
design, data input coordination)
© 2011 Phil Krylov (programming,
technical support)