The Global
Lexicostatistical Database: A Quick Tutorial
This is a quick "Getting Started" guide on how to navigate
around the GLD and make use of its content and features.
For additional explanation of the structure and methodology of the project,
please check the adjacent Global Lexicostatistical
Database: General Description page instead.
1. BROWSE
1.2. Switching
between List and Table views
1.3. Displaying
/ hiding comments
1.4. Viewing language and database information
1.5. Accessing
etymological information
1.6. Sharing
thoughts and reporting problems
2. SEARCH
2.1. Basic
search options
2.2. Finding a particular Swadesh item in one or more languages
2.3. Forming
language- or string-specific queries
3. BUILD
3.1. Basic tree-building options
3.2. Advanced parameters of tree-building
4. SAVE
4.1. View
and download wordlists in PDF format
4.2. View
and download wordlists in MS Excel format
GENERAL LIST OF THINGS TO DO
Currently, the GLD offers the following services to its users:
— BROWSE: look through 100
(110)-wordlists of various language groups;
— SEARCH: look up specific
entries in single or multiple databases;
— BUILD: automatically
construct pictures of genealogical trees for groups of languages;
— SAVE: download the
wordlists of your choice in PDF or Excel form to your computer.
1. BROWSE
From the title page of the GLD, click on Database list. You will find yourself on the main database list page of the site. The two main options are:
1. View a single wordlist for a single language (dialect), or any pair
of wordlists for comparison with each other. To do this, locate the heading Lists for specific languages, select Language 1, (optionally) Language 2, and press the View
button:

2. View a whole set of wordlists from languages belonging to a single
language group. To do this, locate the heading Multi-language lists, select the wordlist database of your choice,
and press View:
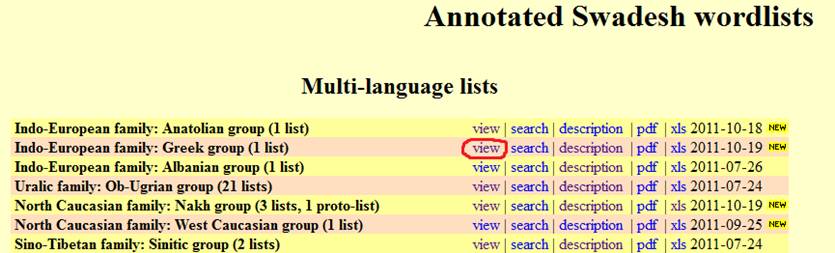
Performing any of these actions will take you to the corresponding wordlist page. (Note that these pages
are not stored on the site as fixed HTML files, but are automatically
generated upon demand from StarLing databases.)
1.2.
Switching between List and Table views
By default, the wordlists on wordlist pages are shown in List mode. In this mode, lexical
information from different languages is arranged vertically, with each next
word displayed on the next line of the list, e. g.:
You can also switch to Table
mode, in which lexical information from different languages is aligned
horizontally (this is much more visually convenient for databases with small
numbers of languages, but can be quite cumbersome for multi-language files). To
do this, click on the Change viewing
parameters link in the top left corner of the wordlist page (the same link
is also included on the main database list page). A new window will open. In
this window, check the Use tables
box and click Change. You will
return to the wordlist page once again, but the same entry will now look as
follows:

Note: If you have cookies enabled in your browser,
the results of your choice will be remembered for all the following sessions.
To return to List view, simply go
back to the parameters page, uncheck the Use
Tables box and click Change
again.
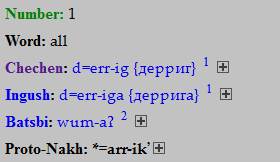
1.3.
Displaying / hiding comments
All of the words on GLD lists are always accompanied
by comments. By default, they are hidden from view. To read any particular
comment on a particular entry, find the small squared
plus sign next to
that entry and click on it. For instance, clicking on the plus sign in the
following entry (from the Anatolian group database)...

...will make it «unfold» as follows:

To hide back the comment, click on the squared minus sign.
Naturally, you may want to unfold all
the comments at once. To do that,
find the Show all notes option at
the top of the displayed wordlist and click on it. (Warning: this might make your screen quite cumbersome if the number
of wordlists within the group you are browsing is rather large). To hide them
back, click on the Hide all notes
option.
1.4.
Viewing language and database information
Each database in the GLD is accompanied by a limited amount of textual
information (list and brief description of data sources; notes on phonetic
transcription and transliteration; name(s) of the person/people responsible
for the compilation, etc.).
If you have already generated a wordlist page and are in the process of
viewing it, you can make this information unfold directly on the wordlist
page. Simply click on the Show database description link (located next to Show All Notes | Hide All Notes). To hide the description once again, click on the Hide database description link to the
right.
Alternately, you may want to use the Description link for the corresponding database on the main database list page:
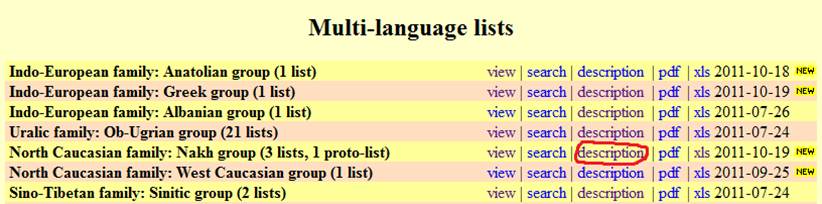
Clicking on this link will take you to a separate page that only contains
the database description for the wordlist. You will have to use your browser's Back button to go back to the main
database list page.
Note also that each language, represented in the database, is also
linked to the basic sociolinguistical information on it at the Ethnologue
website. It can be directly accessed from any wordlist page. Just click on the
name of the language that you are interested in at the top of the Table (in Table view) or List (in List view):

This click will take you directly to the corresponding page of the Ethnologue. You will have to use your
browser's Back button to return to
the wordlist page.
1.5.
Accessing etymological information
Some (although far from
all) of the GLD Swadesh wordlists for particular language groups are linked to
their corresponding etymological dictionary databases that are located in the
main section of the «Tower of Babel» website. If a certain word on the list
corresponds to an etymological entry in one of these databases, this word will
appear as a hyperlink on all of the generated wordlist pages and search result
pages. Clicking on it will take you directly to its etymology. For instance,
clicking on the Chechen word yuq̓ 'ashes' in the wordlist below

will take you to a freshly generated page that contains the following
entry from the etymological database of Proto-Nakh (by Sergei Starostin and
Sergei Nikolayev), where additional comparative and historical information
about the word in question will be available:

Hit the Back button of your
browser to return to the Nakh wordlist page.
If no etymological database for the language group in question is
available on the Tower of Babel site, all of the words on the lists will appear
as plain text (rather than hyperlinks).
1.6.
Sharing thoughts and reporting problems
It is quite possible that,
at one point or another, you may encounter an error in one of the databases,
or, if you are a specialist on a particular language, may want to share some information
that could make an important addition to the commentaries. To do this without
leaving the wordlist page, just click on the Send comment or report error link in the top left corner of the
page. A simple comment form will appear:
Simply fill in your
personal data (an E-mail address is necessary so that we may be able to contact
you back), enter your error report / improvement suggestion in the main body of
the form and click on Send Comment.
Your message will be automatically delivered to the GLD coordinators. The
script automatically marks the name of the wordlist page from which the message
has been sent. We will do our best to check the message, implement the
necessary changes if they are deemed necessary, and get back to you with an
answer as soon as possible.
2. SEARCH
The main
search algorithm for the GLD is a version of the search algorithm employed for
the general etymological databases in the main section of «Tower of Babel»,
significantly modified to better fit the purposes of the GLD.
There are
two general modes of searching for specific information. You can look things up
in one particular wordlist, or you
can search in several (by default — all)
the databases at once. We will first illustrate the main features of the
«single database search» procedure.
Select a
database on the main database list page and click the corresponding Search link, e.g.:
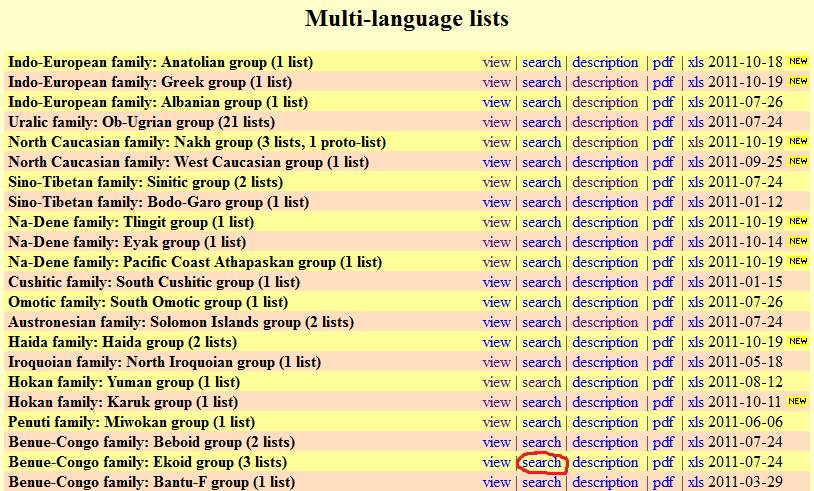
Clicking on
this link will open the Search
screen:
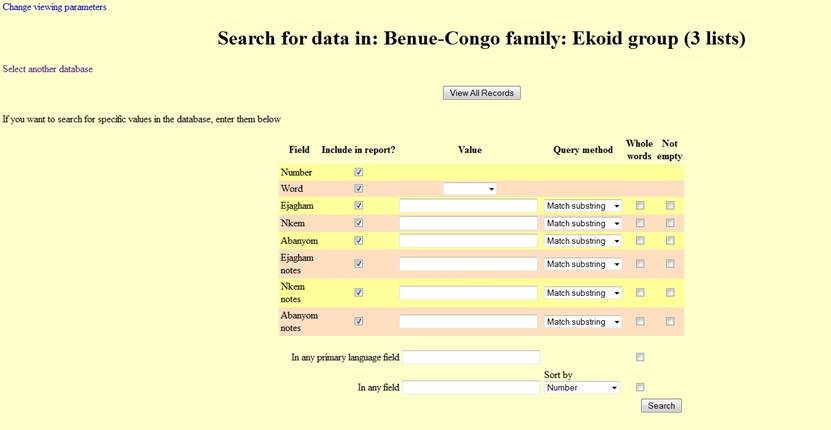
From this
screen, it is possible to generate two types of queries: (a) finding the equivalents
for one of the 110 Swadesh items in all the languages on the list; (b)
language- or string-specific queries with various degrees of complexity.
2.2.
Finding a particular Swadesh item in one or more languages
To find the
equivalents for one of the 110 Swadesh items in all the languages on the list,
move your cursor to the first (shortest) white line in the table (intersection
of «Word» and «Value»). Clicking on the small triangle will open a scrolling
window, from which you can select one of the items:
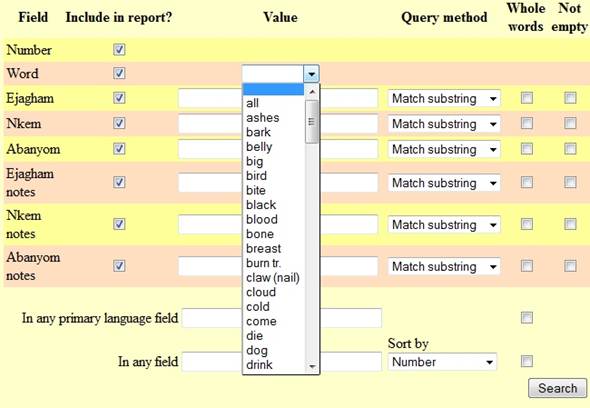
Then click on the Search
button. This will open a new window where your search results will be displayed
in list or in table form, depending on your current settings. For instance, if
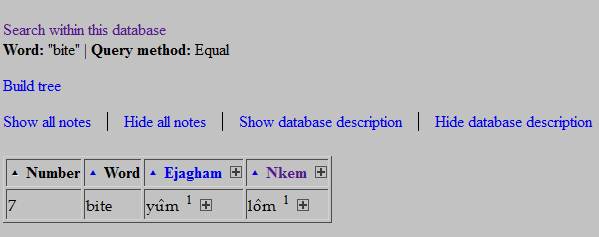
you have selected 'bite', you should get the following query result (in table mode):
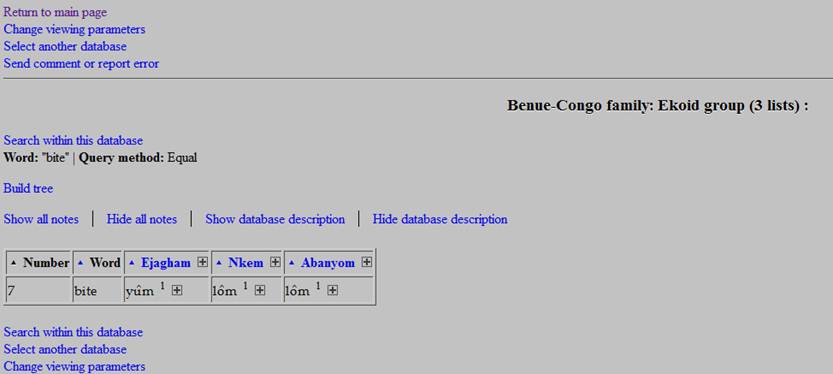
You may want to see the required word in some rather than all the languages of the group (especially understandable if the
group in question contains more languages than can fit on one screen). To do
that, before pressing Search, uncheck the small Include in report? boxes next to the names of the languages that
you do not need in your query results. Thus, unchecking the box next to Abanyom
in our current example will make the computer ignore Abanyom data, with the
result looking as follows:
2.3.
Forming language- or string-specific queries
Looking up
one particular Swadesh item on the wordlist is fun, but not altogether useful,
since it can also be very quickly done while simply browsing through the entire
database. Much more important is the ability to form various specific queries,
such as (using the same Ekoid database as an example):
Find
all of the Ejagham words that contain the sound k;
Find
all of the Ejagham words that begin with k-;
Find
all the words that contain r in Ejagham and d in Abanyom;
Find
all the words in all listed Ekoid languages that include the sequence la;
Find
all the Swadesh items for which the Abanyom equivalent is not attested;
Find
all the Swadesh items in all listed Ekoid languages with noted cases of
polysemy, etc.
In order to
form such queries (which can be even more complex depending on the user's
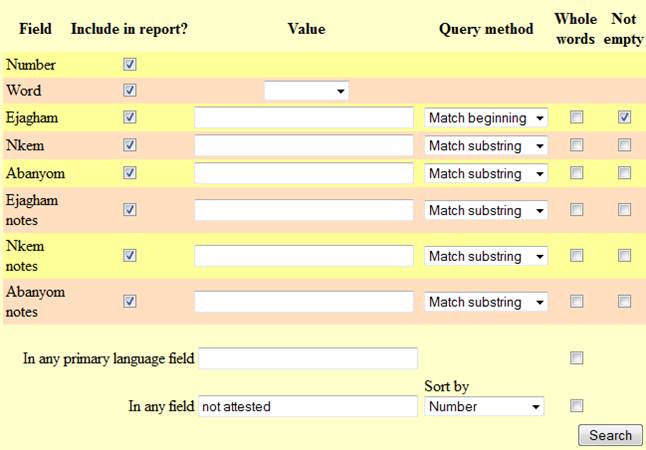
wishes), it is necessary to understand the search parameters. Let us look at
the query input screen more closely:
The legend is as follows:
FIELD: Name of the fields that
contain all the information. This includes numbers of the Swadesh items, from 1
to 110 (Number), the items
themselves (Word), their principal
equivalents in all the languages in the database (Ejagham, Nkem, Abanyom), and, separately, notes on all
these languages (Ejagham notes,
etc.).
INCLUDE IN
REPORT?: Checking
and unchecking these little boxes next to each field will make the respective
fields appear or disappear in your query result.
VALUE: This is where you enter
what you are searching for — a string
of symbols (a letter, a sequence
of letters, a word, or even a phrase, although phrases can be encountered only
in «Notes» fields). Note that you may fill in as many fields as you want. For
instance, a query like this...

...will yield only those
Swadesh items, the equivalents for which have a y in Ejagham, Nkem, and
Abanyom. (The logical operation OR is not yet incorporated into the search
algorithm).
QUERY METHOD: There are four different ways in which
the search algorithm can understand the input strings of characters:
|
Match substring: |
By default, the algorithm just gives you all the entries in which the
string has been encountered. Thus, looking for the string y in Ejagham will yield such words as
ò=yà 'belly', yûm
'bite', è=yǜg
'cold', yûi
'kill', ɛ̀=yâ
'year', etc. |
|
Match beginning: |
The algorithm only returns the entries in which the
string has been encountered in the initial
position. Therefore, looking for y
in Ejagham will yield such words as yûm 'bite', yûi 'kill', but not ò=yà 'belly' or è=yǜg
'cold', since the latter do not begin with y. |
|
Like
beginning: |
The algorithm returns the entries whose beginning is
not only identical with the input
string, but is also phonetically
similar to it. (Definition of what constitutes «phonetic similarity» in
StarLing algorithms can be found here, in section 2).
Thus, looking for the string at in
Ejagham will yield such words as ɛ̀tí-ɛ̀tî 'many'
and ɛ̂d
'we', since they are judged by the machine as phonetically similar to at. |
|
Like
substring: |
The algorithm returns the entries any part of which (not just the
beginning) is phonetically similar to the input string. Thus, looking for the
string t in Ejagham, in addition
to ɛ̀tí-ɛ̀tî
'many' and ɛ̂d 'we', will yield such words as =kpídì
'near' and =sǝ́dɛ́
'say', because their middle parts (-di, -dɛ) are phonetically similar to t. |
WHOLE WORDS: The algorithm will only return those results
in which the string that you have entered forms an entire word, not part
of the word. Thus, looking for the string ka in Ejagham with the option Whole
words unchecked will return two results: =kárè
'give' and ka-
'not'. If the option Whole Words is
checked, the algorithm will only return ka-, but not =kárè.
NOT
EMPTY: This option only makes sense if you specify conditions for several
fields at once. For instance, you may want to look up all the Swadesh items, (a)
whose equivalents in Ejagham contain the letter r and (b) whose equivalents both in Nkem and Abanyom are attested (i. e. are not represented
by empty cells). You then form your query as follows:
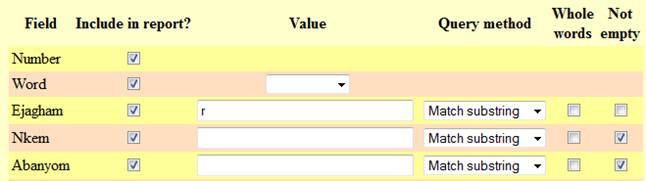
i. e. put r in Value for Ejagham and check the Not empty boxes on Nkem and Abanyom. If
you do not check these boxes, one of
the query results that you will get will be:

i. e. a word with r in
Ejagham, but no attested equivalents in either Nkem or Abanyom. If you check
both boxes (or even one), this particular result will not appear, but others
will, e. g.:
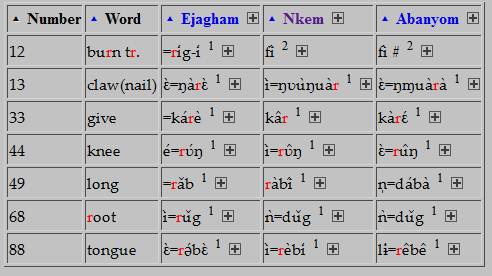
It is also
possible to make good use of some of the «rigid» format peculiarities employed
in the annotations. For instance, in most cases when a certain word shows
polysemy, the annotation to that word contains the formula: «Polysemy: 'meaning
1 / meaning 2 / ... / meaning n'».
Thus, if you want to find all instances of polysemy in Ekoid languages, your
query has to be as follows:
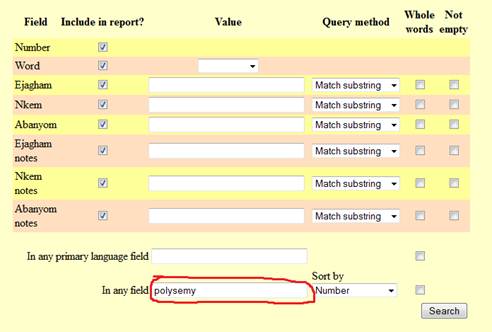
This prompts
the script to yield all the database entries that contain the word 'polysemy'
in any field of the database,
including annotation fields. The result (with annotations «unfolded») will be
as follows:
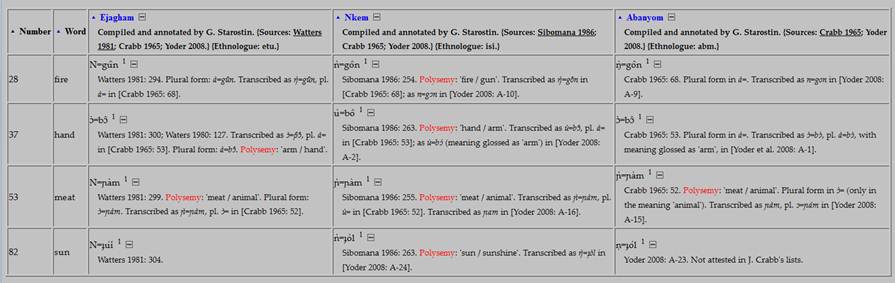
... meaning
that, for the given three Ekoid languages, altogether four instances of
polysemy have been recorded in the database. (This may not, of course, be an
exhaustive list: the correctness and fullness of information on polysemy
depends significantly upon the quality of the source material).
3. BUILD
3.1. Basic tree-building options
If there are two or more different wordlists entered in a single
language group database, the GLD allows the user to automatically construct a genealogical tree of all the languages
in the group, based on calculating the percentages of lexical matches («cognates»)
and using the «neighbor joining» method to convert this data into tree-form.
Along the way, one of several possible glottochronological formulae is also
applied to the data, establishing approximate absolute separation dates for
various languages included in the tree. The resulting tree appears as an image
and may be saved to your computer.
To build a tree in on-line mode, open any single database (e. g. Nakh)
in View mode. Locate the Build tree option:
Clicking on Build tree will uncover the following
set of parameters:

Click on Build to get the picture of a
genealogical tree for the language group:

The numbers
on top represent glottochronological dating (in millennia). This picture is
interpreted as follows: «Proto-Nakh» splits in two branches, Batsbi and
Chechen-Ingush, approximately at the very beginning of the 1st millennium A.D.
(= 0.00); later, Chechen and Ingush split from each other sometime in between
750 (= 0.75) and 1000 (= 1.00) A.D.
By default,
the picture is produced in Scalable Vector Graphics (SVG) format. This is very
convenient for certain purposes of analysis; however, SVG images are not always
easily saved to disc from within browsers. You may choose to change the image
format to Portable Network Graphics (PNG) instead, simply by switching the
Tree format (SVG / PNG) option to PNG.
Click on the
Close option to remove tree images
and tree-building parameters from the screen.
3.2. Advanced parameters of tree-building
There is no single way of building an «intrinsically correct»
genealogical tree of languages based on percentages of lexicostatistical
matches: the best results are always attained by comparing several different
trees. The following parameters of the on-line tree-building mechanism are
flexible and can be «manipulated» by the user before generating a picture:
a) Method: For now,
you can choose between three different options:
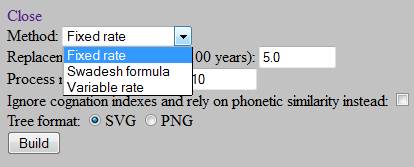
Fixed rate – The default method consists of applying the «basic»
formula of glottochronology (borrowed by M. Swadesh from the methodology of radiocarbon
analysis, and significantly modified by S. Starostin; see here for a detailed
explanation) to the matrix of cognate percentages. «Fixed rate» implies the
idea of a constant rate of lexical replacement, which, by default, equals 5.0
(i. e. approximately 5 out of 100 Swadesh items replaced in any language per 1
millennium).
Variable rate – A slightly more complicated method that should be
applied whenever the calculations are performed on an abbreviated version of a
Swadesh list (e. g. 50 rather than 100 items). Here, individual replacement rates are assigned to each item on the list, with those that are empirically known to be
more stable over time (e. g. 'I', 'thou', 'eye', 'name', etc.) assigned slower
rates of replacement than those whose meanings, on the average, «fluctuate» far
more frequently (e. g. 'earth', 'bark (of tree)', 'yellow', 'small', etc.).
Swadesh formula – The original «classic»
version of the glottochronological formula that does not make use of additional
corrections, introduced by S. Starostin. Rate of replacement, by default,
equals 14 words per millennium.
b) Replacement rate: When using Fixed rate or Swadesh formula methods to generate the tree, it is possible to
manually «fix» the average replacement rate, changing it from its default
values of 5 words per 1000 years (Fixed rate) or 14 words per 1000 years
(Swadesh formula). Normally, this parameter should not be tampered with, but it
has been included nevertheless, for experimental purposes.
c) Process meanings until rank: In
the «Variable rate» method, each Swadesh item is assigned a «rank» (from 1 to
100, or from 1 to 110 in the slightly expanded variant of the list) based on
its average stability across the world (see here for a
detailed explanation and a list of the rankings). It is possible to limit the
data to a subset of the 100(110)-wordlist that only includes the more stable
items, e. g. change 110 to 50 or any other number (although any number less
than 40 ~ 50 will most likely yield unrealistic
results). For reliable results, tampering with this parameter is only
recommended in conjunction with the Variable
rate method of tree generation.
d) Ignore cognation indexes
and rely on phonetic similarity instead: Putting a check mark in this
window will make the tree-building ignore all the etymological cognation
indexes that have been manually entered by researchers during the construction
of wordlists and, when browsing through the database, are visible as
superscript indexes next to individual words. Instead, the algorithm will try
to «objectively» re-assign cognation indexes to words, based on trivial
phonetic similarity between their consonantal structures. (See here for a more detailed
explanation), and use these indexes to calculate dates of divergences and
generate a tree. Please note that, in
most cases, the results of this method will be historically wrong rather than simply unreliable; it is included mainly for experimental purposes.
Each different combination of these parameters will, most likely, yield a
different tree. Having entered in your modifications, press the Build button once again to re-generate
the picture.
4. SAVE
4.1. View and download wordlists in PDF format
All of the
wordlist data published in the GLD can be saved on your computer for offline use.
For the users' convenience, we currently include downloadable wordlists in two
formats: PDF and Microsoft Excel.
To open a
wordlist in PDF format from within your Internet browser (if you have an Adobe Acrobat
plugin installed), go to the main database list page and left-click on the pdf option next to the wordlist of your
choice, e.g.:
If you wish
to save the .pdf file to your computer, right-click the same link and choose
the Save link as... option.
Each PDF
file stores the full contents of the corresponding online database, including
the general file description and all of the annotations. It is paginated and
can be easily printed out. PDF files, however, cannot be edited for the user's
own purposes.
4.2. View and download wordlists in MS Excel format
To save the
wordlist in MS Excel format, go to the main database list page and either
left-click on the xls option next to
the wordlist of your choice, or right-click on it and choose the Save link as... option:

Each Ms Excel file stores the full contents of the
corresponding online database (including all the annotations), except for the general file description. It is open for editing and can be
used for various further purposes.
Note: In order to view all the symbols correctly, you must download and install the default
font for the GLD: Starling
Serif. Most of the transcriptional symbols are standard Unicode and will be
visible with any Unicode fonts, but some (e. g. «monolithic» combinations of
letters with several diacritics) are only found in the user-defined area of
Starling Serif and will show up as squares or other kinds of «dirt» if the
proper font is not installed.